Databricks Delta Live Tables vs Classic ETL: When to Choose What?
As data platforms mature, teams often face a familiar question:
Should we continue with classic ETL pipelines, or move to Delta Live Tables (DLT)?
Both approaches work. Both are widely used. The real challenge is knowing which one fits your use case, not which one is newer or more popular.
In this blog, I’ll break down Delta Live Tables vs classic ETL from a practical, project-driven perspective, focusing on how decisions are actually made in real data engineering work.
Classic ETL in Databricks
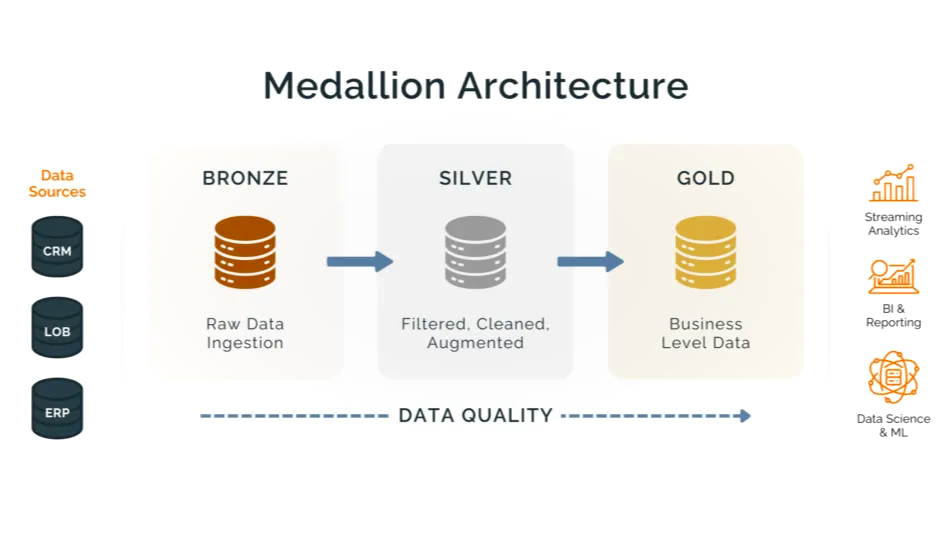
Classic ETL in Databricks refers to pipelines where engineers explicitly control each stage of data movement and transformation. The pipeline logic is written imperatively, meaning the engineer decides how data is read, processed, validated, and written.
Architecturally, classic ETL pipelines usually follow the Medallion pattern:
- a. Raw data is ingested into Bronze tables
- b. Data is cleaned and standardized into Silver tables
- c. Business-ready aggregates are written to Gold tables
Each step is executed explicitly, often as independent jobs or notebooks. Dependency management, error handling, retries, and data quality checks are all implemented manually or through external orchestration tools.
This approach gives teams maximum freedom. Complex ingestion logic, conditional transformations, API integrations, and custom performance tuning are easier to implement because nothing is abstracted away. However, this flexibility also means consistency and governance depend heavily on engineering discipline.
We implemented a Classic ETL pipeline in our internal Unity Catalog project, migrating 30+ Power BI reports from Dataverse into Unity Catalog to enable AI/BI capabilities. This architecture allows data to be consumed in two ways – through an agentic AI interface for ad-hoc querying and through Power BI for governed, enterprise-grade visualizations.
We chose the ETL approach because it provides strong data quality control, schema stability, and predictable performance at scale. It also allows us to apply centralized transformations, enforce governance standards, optimize storage formats, and ensure consistent semantic models across reporting and AI workloads -making it ideal for production-grade analytics and enterprise adoption.
Delta Live Tables
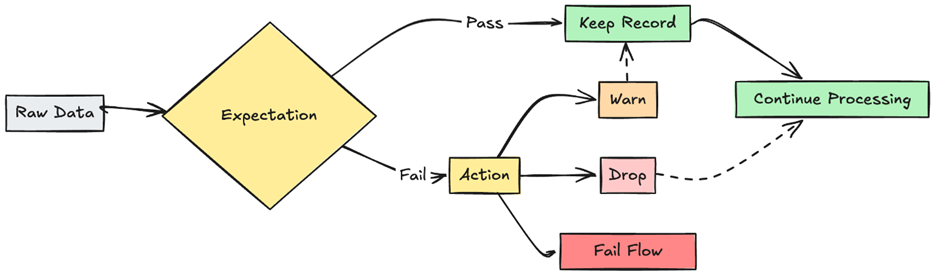
Delta Live Tables is a managed, declarative pipeline framework provided by Databricks. Instead of focusing on execution steps, DLT encourages engineers to define what tables should exist and what rules the data must satisfy.
From an architectural perspective, DLT formalizes the Medallion pattern. Pipelines are defined as a graph of dependent tables rather than a sequence of jobs. Databricks automatically understands lineage, manages execution order, applies data quality rules, and provides built-in monitoring.
DLT pipelines are particularly well-suited for transformation and curation layers, where data is shared across teams and downstream consumers expect consistent, validated datasets. The platform takes responsibility for orchestration, observability, and failure handling, reducing operational overhead.
In my next blog, I will demonstrate how to implement Delta Live Tables (DLT) in a hands-on, technical way to help you clearly understand how it works in real-world scenarios. We will walk through the creation of pipelines, data ingestion, transformation logic, data quality expectations, and automated orchestration.
The Core Architectural Difference
The fundamental difference between classic ETL and Delta Live Tables is how responsibility is divided between the engineer and the platform.
In classic ETL, the engineer owns the full lifecycle of the pipeline. This provides flexibility but increases maintenance cost and risk. In Delta Live Tables, responsibility is shared: the engineer defines structure and intent, while Databricks enforces execution, dependencies, and quality.
This shift changes how pipelines are designed. Classic ETL is optimized for control and customization. Delta Live Tables is optimized for consistency, governance, and scalability.
When Classic ETL Makes More Sense
Classic ETL is a strong choice when pipelines require complex logic, conditional execution, or tight control over performance. It is well suited for ingestion layers, API-based data sources, and scenarios where transformations are highly customized or experimental.
Teams with strong engineering maturity may also prefer classic ETL for its transparency and flexibility, especially when governance requirements are lighter.
When Delta Live Tables Is the Better Fit
Delta Live Tables excels when pipelines are repeatable, standardized, and shared across multiple consumers. It is particularly effective for silver and gold layers where data quality, lineage, and operational simplicity matter more than low-level control.
DLT is a good architectural choice for enterprise analytics platforms, certified datasets, and environments where multiple teams rely on consistent data definitions.
A Practical Architectural Pattern
In real-world platforms, the most effective design is often hybrid. Classic ETL is used for ingestion and complex preprocessing, while Delta Live Tables is applied to transformation and curation layers.
This approach preserves flexibility where it is needed and enforces governance where it adds the most value.
To conclude, Delta Live Tables is not a replacement for classic ETL. It is an architectural evolution that addresses governance, data quality, and operational complexity.
The right question is not which tool to use, but where to use each. Mature Databricks platforms succeed by combining both approaches thoughtfully, rather than forcing a single pattern everywhere.
Choosing wisely here will save significant rework as your data platform grows.
Need help deciding which approach fits your use case? Reach out to us at transform@cloudfronts.com
