ADF’s Mapping Data flows – How do you get distinct rows and rows count from the data source?
In this blog, we will learn how to get distinct rows and rows count from the data source via ADF’s Mapping Data flows step by step.
Step 1: Create an Azure Data Pipeline.
Step 2: Add a data flow activity and name as “DistinctRows”.
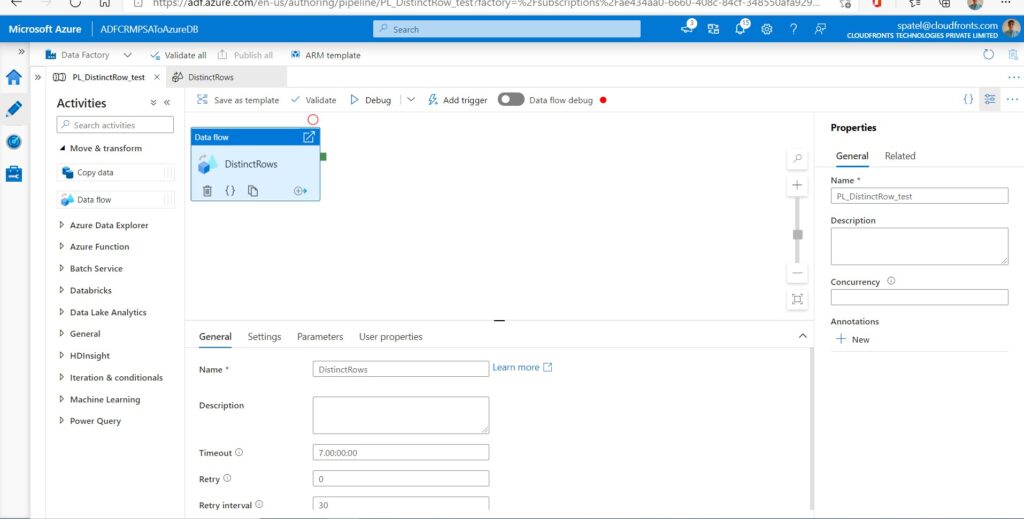
Step 3: Go to settings and add a new data flow. Select the Source Settings tab, add a source transformation, and connect it to one of your datasets.
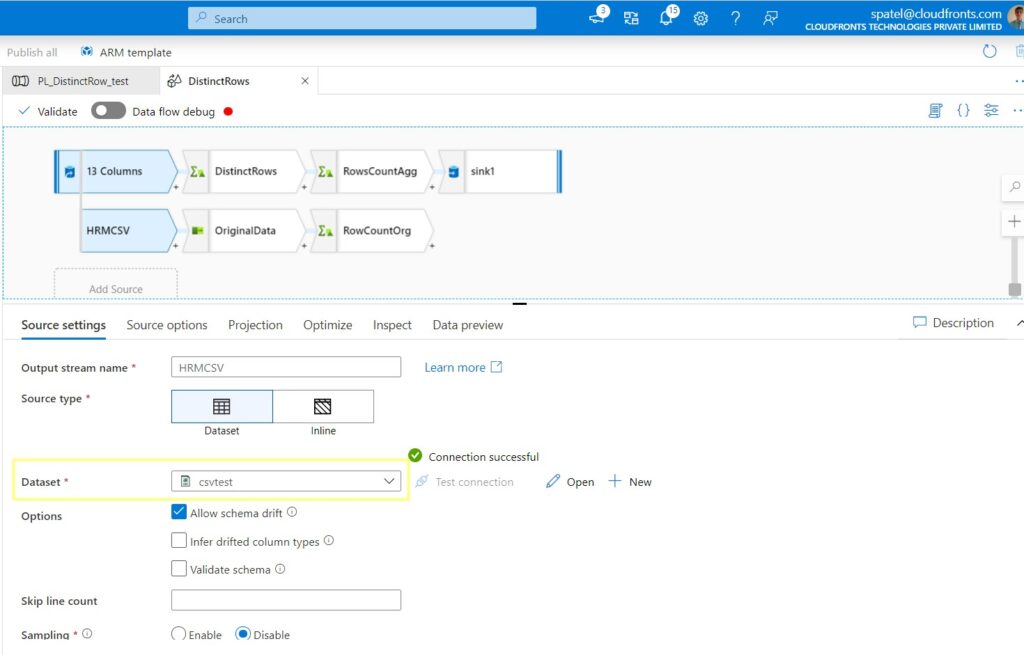
Step 3: In the Projection tab, it allows you the change the column data type. Here I have changed my Emp ID column to Integer.
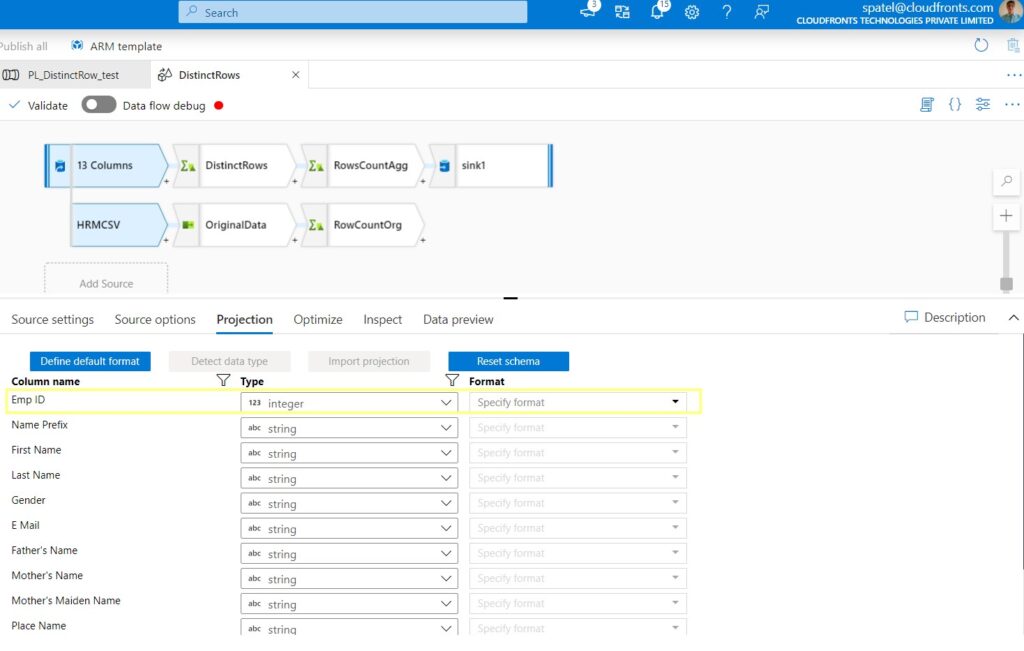
Step 4: In the Data preview tab you can see your data.
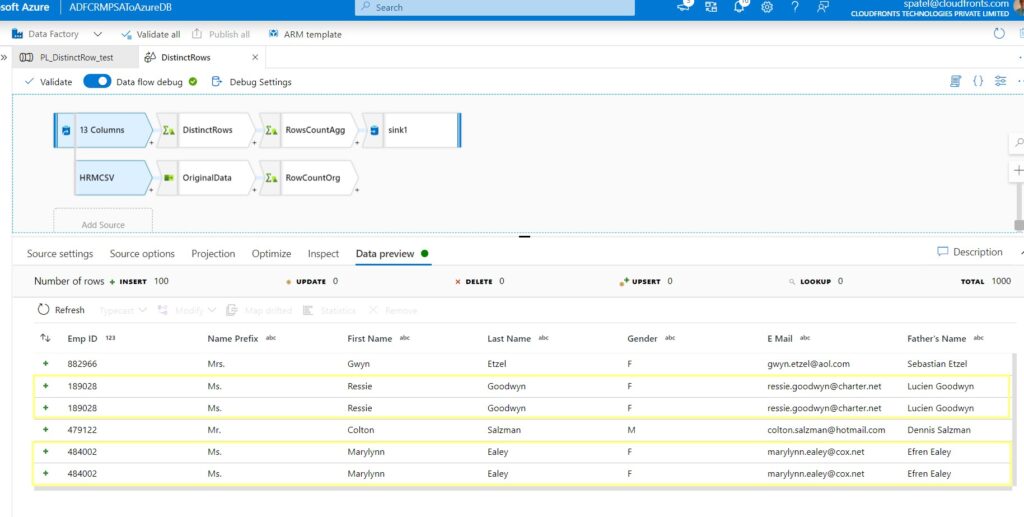
Step 5: Add an Aggregate transformation, named “DistinctRows”. In the group by settings, you need to choose which column or combination of columns will make up the key(s) for ADF to determine distinct rows, here in this demo I pick up “Emp ID” as my key columns.
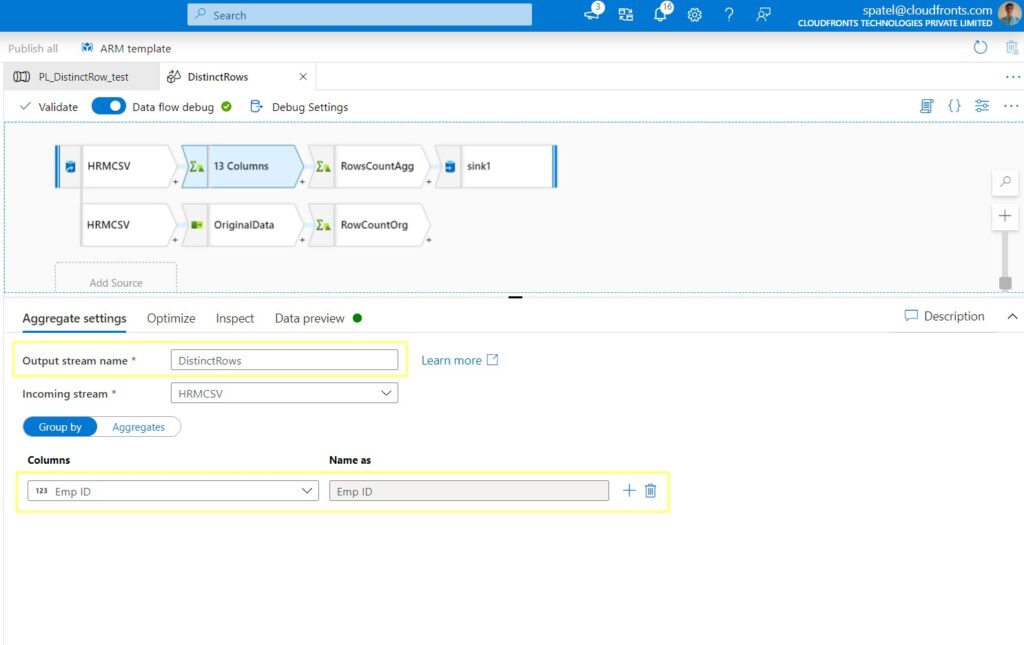
Step 6: The inherent nature of the aggregate transformation is to block all metadata columns not used in the aggregate. But here, we are using the aggregate to filter out non-distinct rows, so we need every column from the original dataset. To do this, go to the aggregate settings and choose the column pattern.
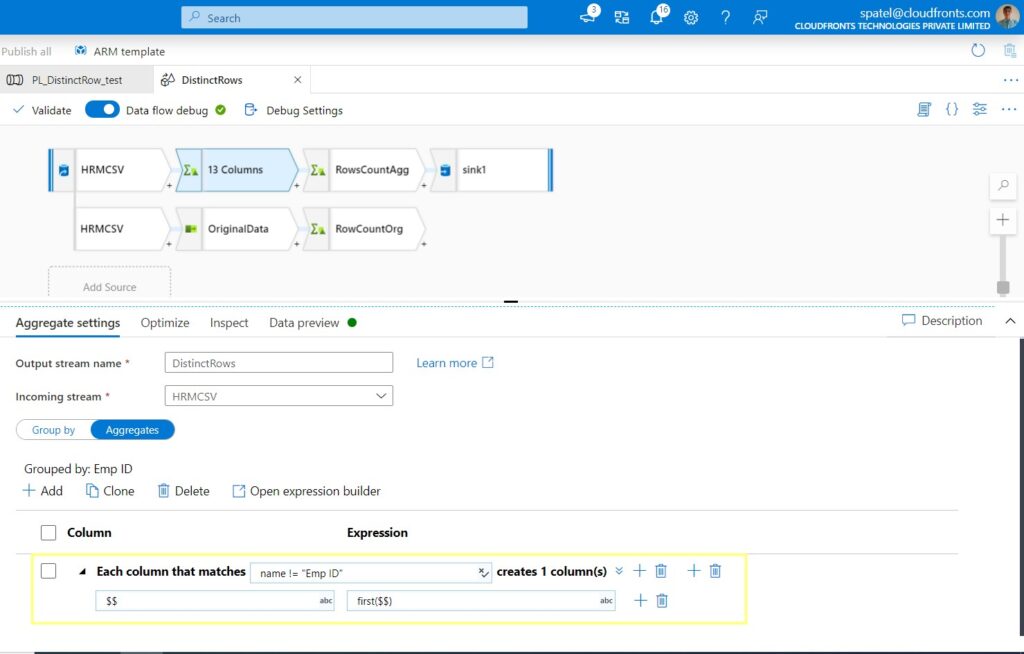
Here, you will need to make a choice between including the first set of values from the duplicate rows, or the last. Essentially, choose which row you want to be the source of truth.
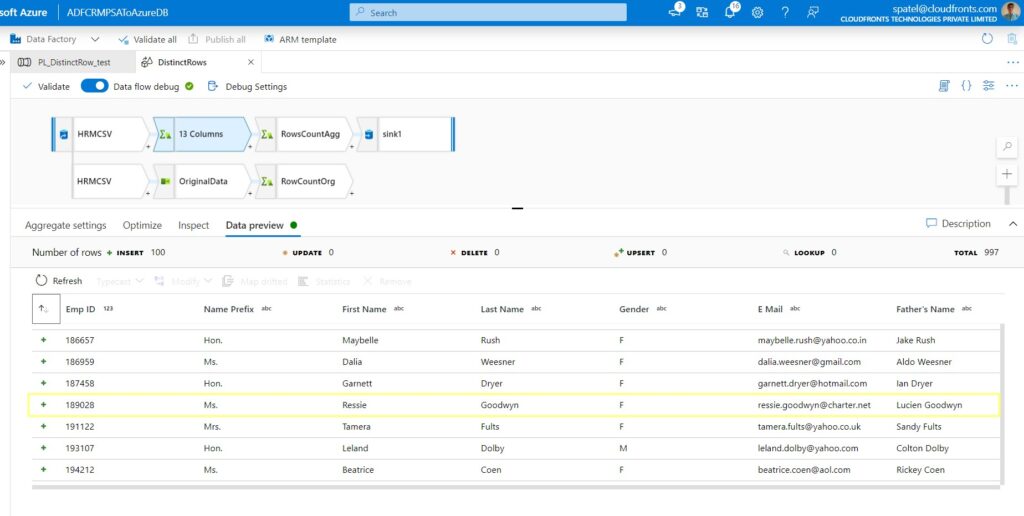
Step 7: That’s all you need to do to find distinct rows in your data, click on the Data preview tab to see the result. You can see the duplicate data have been removed.
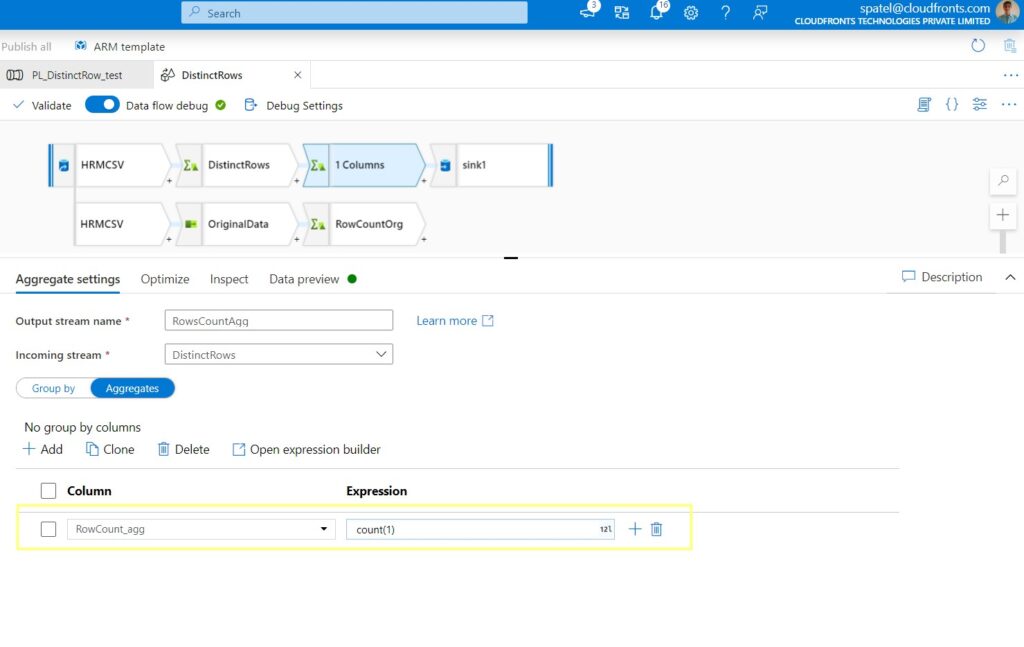
Step 8: The row counts are just aggregate transformation, to create a row counts go to Aggregate settings and use the function count(1). This will create a running count of every row.
Hope this will help.
